
Data quality monitoring: When and where to automate
Explore effective strategies for data quality monitoring to maintain the accuracy and reliability of your analytics, driving informed business decisions.
The tricky thing about bad data is that it’s often hard to find – you might not even realize it’s there. It’s not a different color, it doesn’t make any noise, and it hides so well among millions of rows of good data. It’s often not until a stakeholder pings you that the “numbers look off” that you know you have a problem.
One solution is diligent data quality monitoring — continuous checks and rechecks of data to make sure your data is accurate, consistent, and reliable.
What is data quality monitoring?
Monitoring data quality is like doing detective work – you’re on the lookout for clues that ensure your data is top-notch. (If it makes you feel more confident, you can pretend to be Sherlock Holmes by carrying a pipe and employing a British accent.) Take a look at the key elements that make up this process:
- Accuracy: Make sure your data is correct and true to what it represents. The task here is to continuously check for errors or discrepancies like date formatting or referential integrity. Accurate data reduces the need for time-consuming backtracking.
- **Completeness: **Incomplete data means you don’t have the full picture. Monitoring for completeness involves verifying that all necessary data is present and accounted for, like addresses without zip codes
- **Timeliness: **Is your data “on time”? Are there any broken pipelines causing delayed data? Failure to access timely data risks the ability to make relevant and effective decisions, especially in rapidly changing situations. Make sure you regularly audit your data infrastructure to prevent bottlenecks for optimal decision-making. Mastering data quality monitoring also means being vigilant about the eight dimensions of data quality. You make sure that your analytics are based on data that’s exemplary, giving you confidence in your data and a big high-five from the Datafold team.
Effective techniques of data quality monitoring
As with anything in data engineering, there are several ways of implementing data quality monitoring. Let’s dig into some of the different techniques people use for data quality monitoring.
Real-time monitoring and periodic audits
Real-time monitoring is just what it sounds like. It monitors data in real-time (or close to real-time) to make sure it meets the quality criteria you set. For example, you might set up real-time monitoring to look for incoming inconsistent data volume. This monitoring is often done at the production-level and leverages machine learning models to identify anomalies or inconsistencies in your production data.
Periodic audits, on the other hand, are more like regular health check-ups. Scheduled at intervals, they provide a snapshot of your data’s quality over a period, allowing for a more reflective review of its condition.
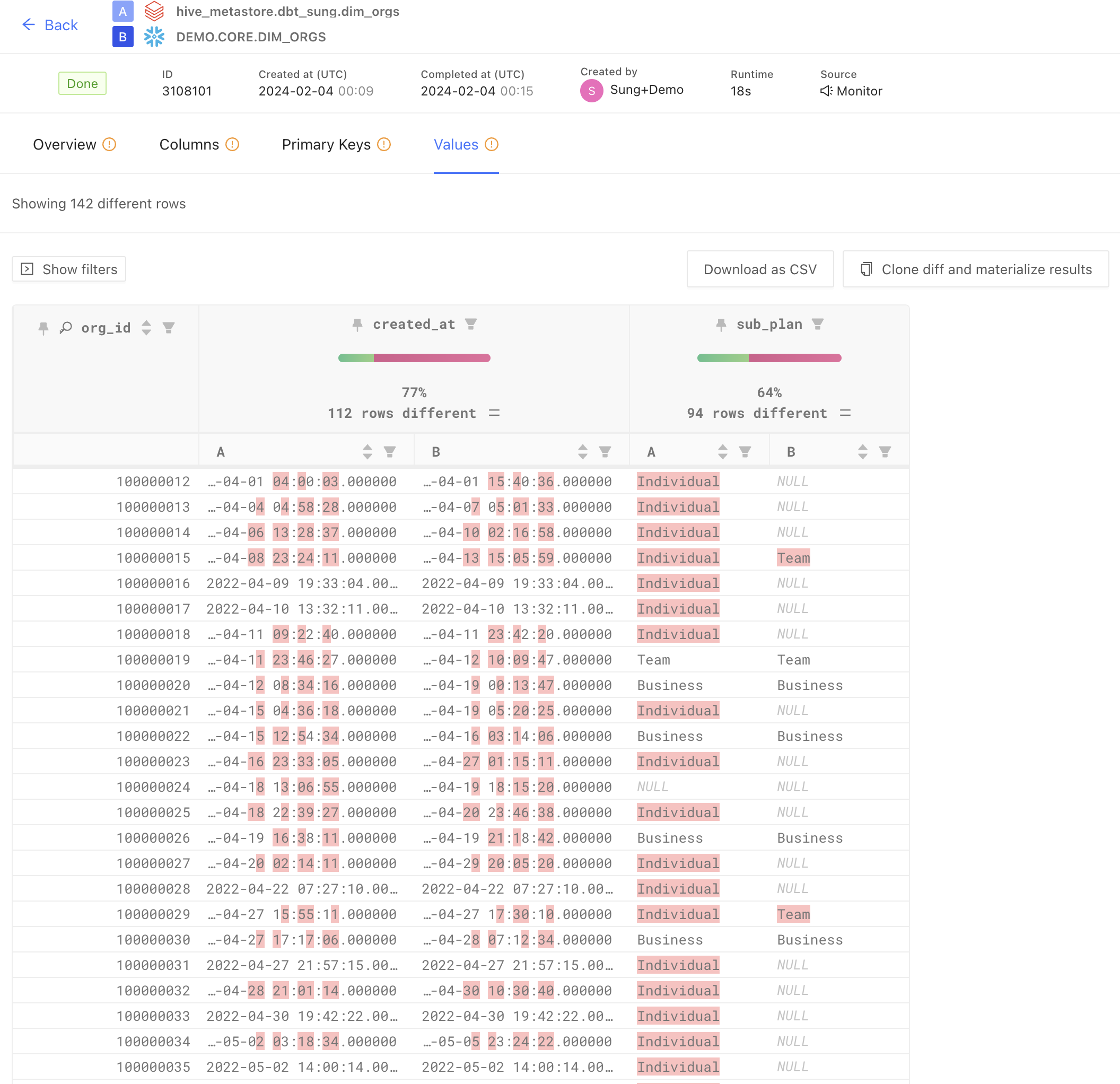
If you want to be more proactive with it, you might use scheduled data diffs between a source and destination in a data replication effort. With Datafold’s new Monitors, you can choose to perform scheduled data diffs across databases to give you a more “real-time” check on the quality of your source replicated data. This allows your team to ensure parity across databases (which is very hard to do!) and be on-top of your backend database to ensure source-level data is accurate and timely.
Automate all the things!
Automated tools are your allies in the data quality battle. They tirelessly scan, analyze, and flag data quality issues, bringing efficiency and accuracy that manual processes just can’t match. They do the heavy lifting, leaving you free to focus on the high-value stuff you wish you could be getting to.
Keep an eye out for features like scalability, compatibility with your existing systems, and the ability to adapt to various data types and sources to make sure they truly meet your organization’s unique data quality needs. We think automation is the clearest path toward standardization and control, so we suggest applying it in as many places as possible (or reasonable).
For example, we are (obviously) huge fans of using CI/CD for your data project workflows and validating source-to-target replication on a continuous basis. It makes a huge difference in overall data quality, keeping errors from entering your pipeline and protecting downstream users from unexpected errors.
Ultimately, embracing automation in data quality management streamlines processes and fosters a culture of continuous improvement and innovation within the organization. By leveraging these tools, teams can anticipate issues, optimize performance, and drive more informed, data-driven strategies that keep the organization competitive.
Challenges in maintaining data quality
Maintaining high-quality data ain’t easy, so you’re sure to encounter various obstacles along the way. The smart play is to not reinvent the wheel. Instead, learn what the pros and cons of each course of action are ahead of time.
The larger the dataset, the greater the problem diversity
Managing diverse datasets is as complex as juggling a bowling ball, a chainsaw, a flaming torch, and a tennis ball. You can’t catch any of them the same way, you can’t throw them with the same effort, yet you have to keep them up in the air to avoid setting your hair on fire — or worse, losing your head.
However, you can confirm quality across such diverse datasets by using robust systems and processes. Using some of the techniques we’ve already discussed (automated testing, data lineage visualizations, data monitoring, CI/CD checks) will be a big step forward for most organizations.
More data, more problems. But you can manage it with intentional automation and software engineering practices.
Human error and system inefficiencies
Even the most sophisticated systems are prone to mistakes if human interaction is involved. Data errors can range from simple data entry slip-ups to more complex misinterpretations of data sets. Coupled with system inefficiencies, these can compromise data quality. To effectively address these challenges, you need to continually optimize and update your systems.
This is where the power of automation comes in. If there’s a chance of human error, take a look at what it would take to either automate your way around it or build in guardrails to minimize the chance of something bad happening. Test all your dbt models every day. Monitor your code. Experiment in pre-production. It’s simple, but will take you a long way if you do it effectively.
Strategies for effective data quality monitoring
Data quality monitoring isn’t just a task to tick off your list – it’s a daily discipline, reliant on a solid base of sophisticated automated systems. Once it’s in place, you can delve into specific strategies and practices that make this discipline more effective over time.
Start by crafting a strong framework, then identify key data metrics, establish quality benchmarks, and assign roles. If there’s manual work involved, combine it with automated tools and processes. Pay attention to the changing needs of your organization and regularly update your strategy. It’s about progress, not perfection (though you should always aim for 100% data quality).