




.avif)
audit_helper vs data-diff for validating dbt model changes
Learn how to validate dbt model changes with dbt's audit_helper package and Datafold's data-diff CLI.


This blog post references the open source data-diff package; as of May 17, 2024, Datafold is no longer actively supporting or developing open source data-diff. For continued access to in-database and cross-database diffing, please check out our free trial of Datafold Cloud.
We’re grateful to everyone who made contributions along the way. Please see our blog post for additional context on this decision.
When you’re updating a dbt model, it’s important to check not only that dbt models run and tests pass, but that unexpected changes in values don’t occur. A dbt test will often not catch such data impacts!
For example, what if a code change led to the strings in a 'first_name' column being duplicated, so that Leo became LeoLeo? Who is LeoLeo, anyway?
There’s not a test for that. You simply can’t create an accepted values test that contains all the right friends in all the right places.

To catch stuff like this, you need to run a data diff. In general, a data diff compares every value between two tables to search for differences. In the dbt context, that means comparing the values in production models to the values in development models.
I’ll walk you through how to make the most of two fully open source and free options for running data diffs: dbt Labs’ audit_helper and Datafold’s data-diff.
dbt’s audit_helper package
audit_helper is a dbt package containing several handy macros that can be used to compare values in dbt models across rows and columns. There is one macro in particular that fits this use case perfectly: the compare_all_columns macro, which compares every value of every column out-of-the-box.
In this example, I’ll compare the values in my development version of 'dim_orgs' to the production version of the same table, after making a few code changes.
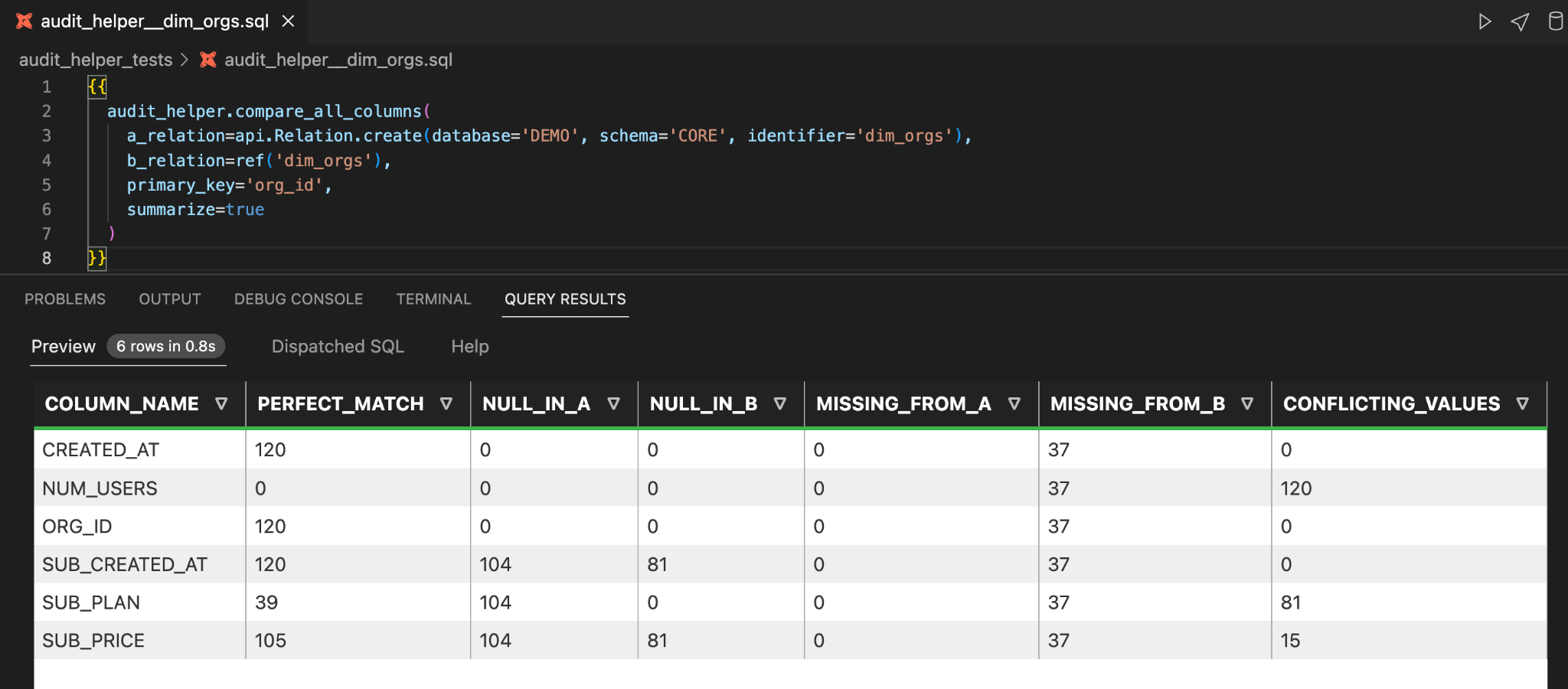
That table identifies important information that helps you see the differences between the two versions of the same table, with A representing production and B representing development:
- PERFECT_MATCH: How many rows in a given column have the exact same value in both versions of the table.
- CONFLICTING_VALUES: How many rows in a given column have differing values for the same primary key.
- NULL_IN_: How many NULL values are in each column.
- MISSING_FROM_: How many primary keys are missing from each version of the table. This will be the same number for every column.
In this example, there are three columns that have conflicting values for common primary keys:
- NUM_USERS: 120 conflicting values
- SUB_PLAN: 81 conflicting values
- SUB_PRICE: 15 conflicting values
These are data differences that can be explained by your code changes!
To investigate these differences in more detail, you can simply reverse the 'summarize' flag.
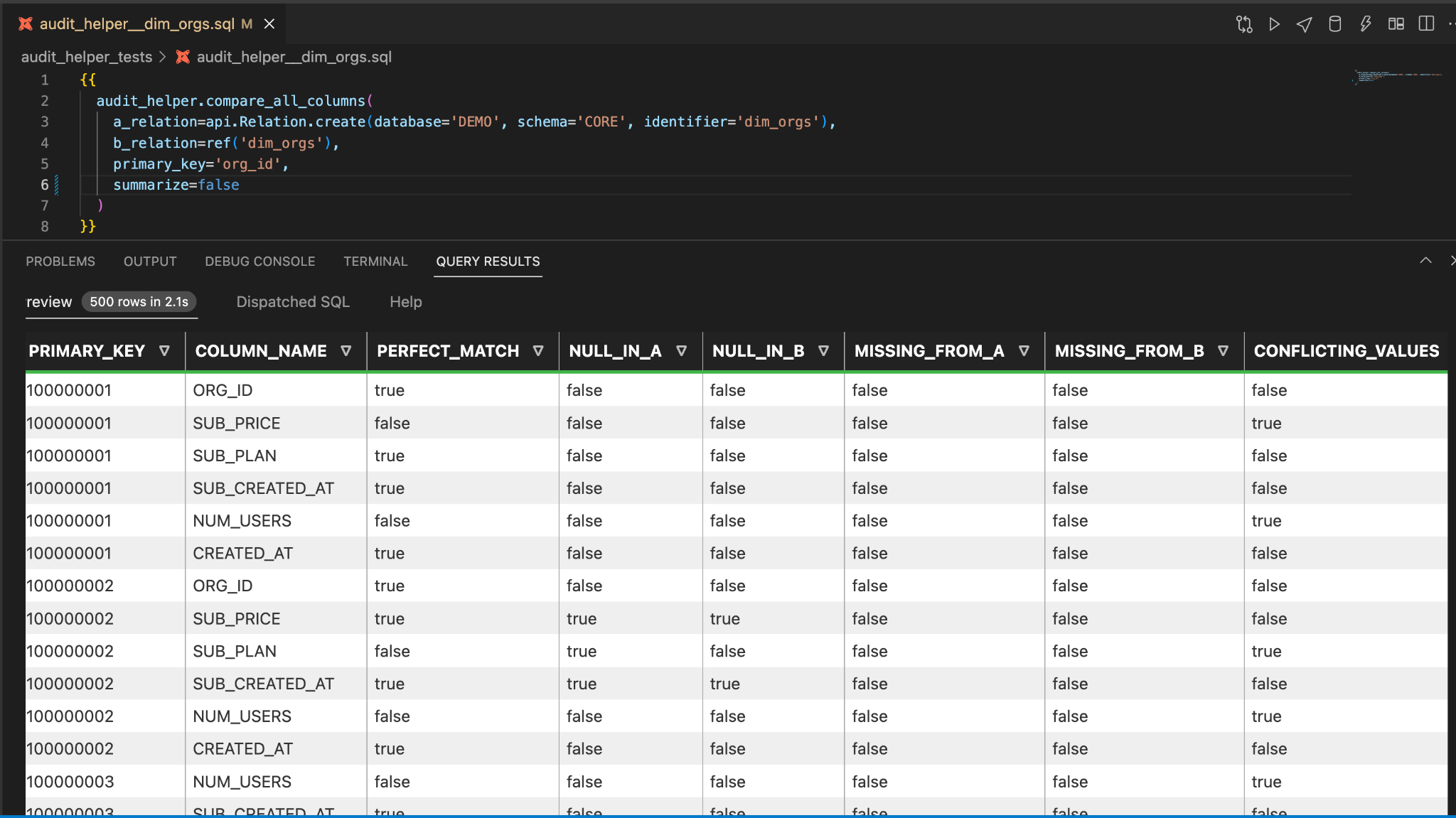
Overwhelming! Yes, it’s not the most readable, but the boolean columns create a powerful structure for exploratory analysis. Let’s get oriented.
There is one row for every combination of primary key and column name. This makes it easy to summarize and count instances of an occurrence, and even join to a table in your warehouse to pull in values from columns.

Exploratory analysis of a specific column’s data diff with audit_helper
Let’s take a look at SUB_PLAN, which has 81 conflicting values. We also see there are 104 NULLs in A, and zero NULL values B.
Is it the case that all of the 81 conflicting values are due to NULLS changing to NOT NULL? It seems possible, but it’s not absolutely clear from the table. For example, 37 of the NULL values could have become missing values, which would leave only 67 conflicting values that could be accounted for by NULLs changing to NOT NULLs.
Let’s check to see how many of the primary keys that are NULL_IN_A are also counted as CONFLICTING_VALUES. When a PK is counted as both NULL_IN_A and CONFLICTING_VALUES, it means that the value changed from NULL to NOT NULL.
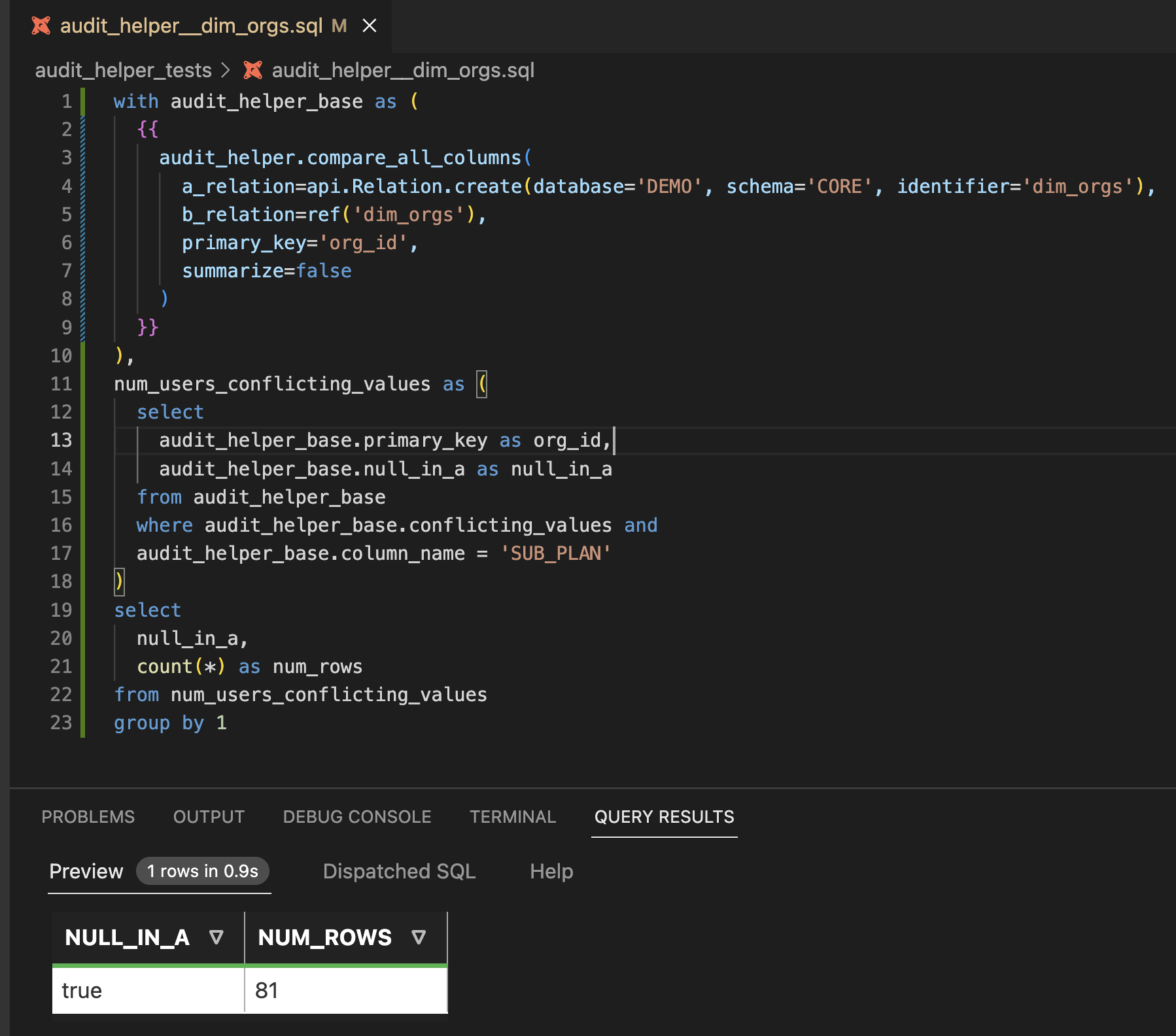
Check it out! All of the 81 primary keys that have CONFLICTING_VALUES are also NULL_IN_A.
Now, let’s see what SUB_PLAN value(s) these rows have in Table B. For this, we’ll actually join the table built by the `compare_all_columns` macro to the dev table.
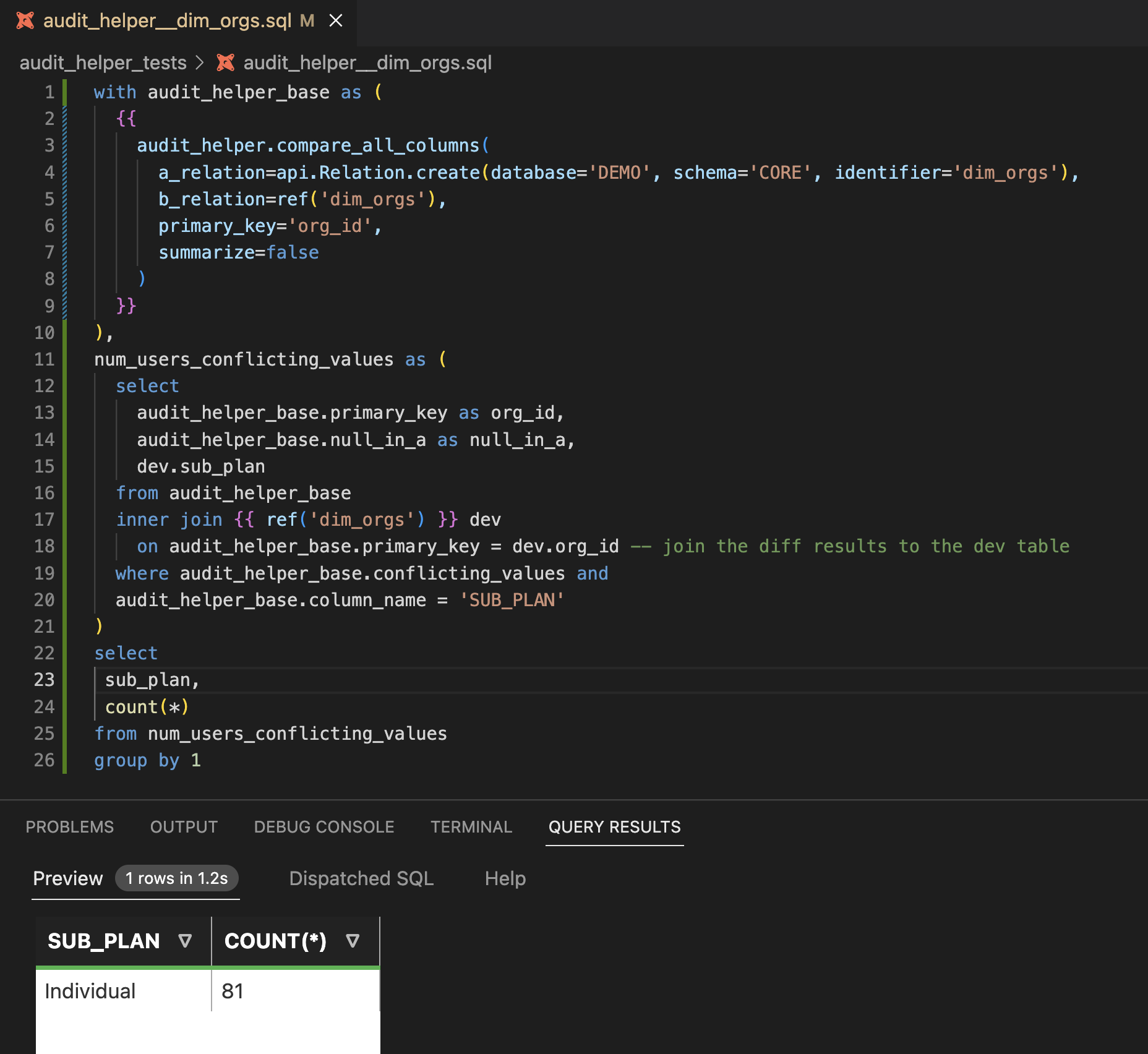
Indeed, all 81 SUB_PLAN values that are NULL in production are now “Individual.” Now, it’s up to you, the dbt developer, to decide whether 81 SUB_PLAN values changing from NULL to “Individual” is an acceptable data impact, or whether more updates to the code are needed.
One last thing. Where should you store all this code? For any analyses you want to save and reuse, I suggest creating a folder in your project called audit_helper where you store sql files containing tests that you then run in development. That way, you can execute these diffs early on in the dbt development process.
Diffing all modified models and downstreams with data-diff
As you can see, you can do a lot with audit_helper, but even in its simplest implementation, there’s a fair amount of code management and manipulation you have to do, and it’s only set up to investigate one model at a time.
Datafold’s open source data-diff + dbt integration offers a different set of tradeoffs. It’s dead simple to get started, and it automatically picks up any models that were run in your most recent dbt run. You don’t have to create or store any files. With just a few simple configurations in your dbt project, you can get started.
This is how data-diff handles the exact same update to 'dim_orgs' that we just walked through. After you’ve edited your models, you can then run a dbt command selecting any number of models and add data-diff –dbt to the command, just like this:
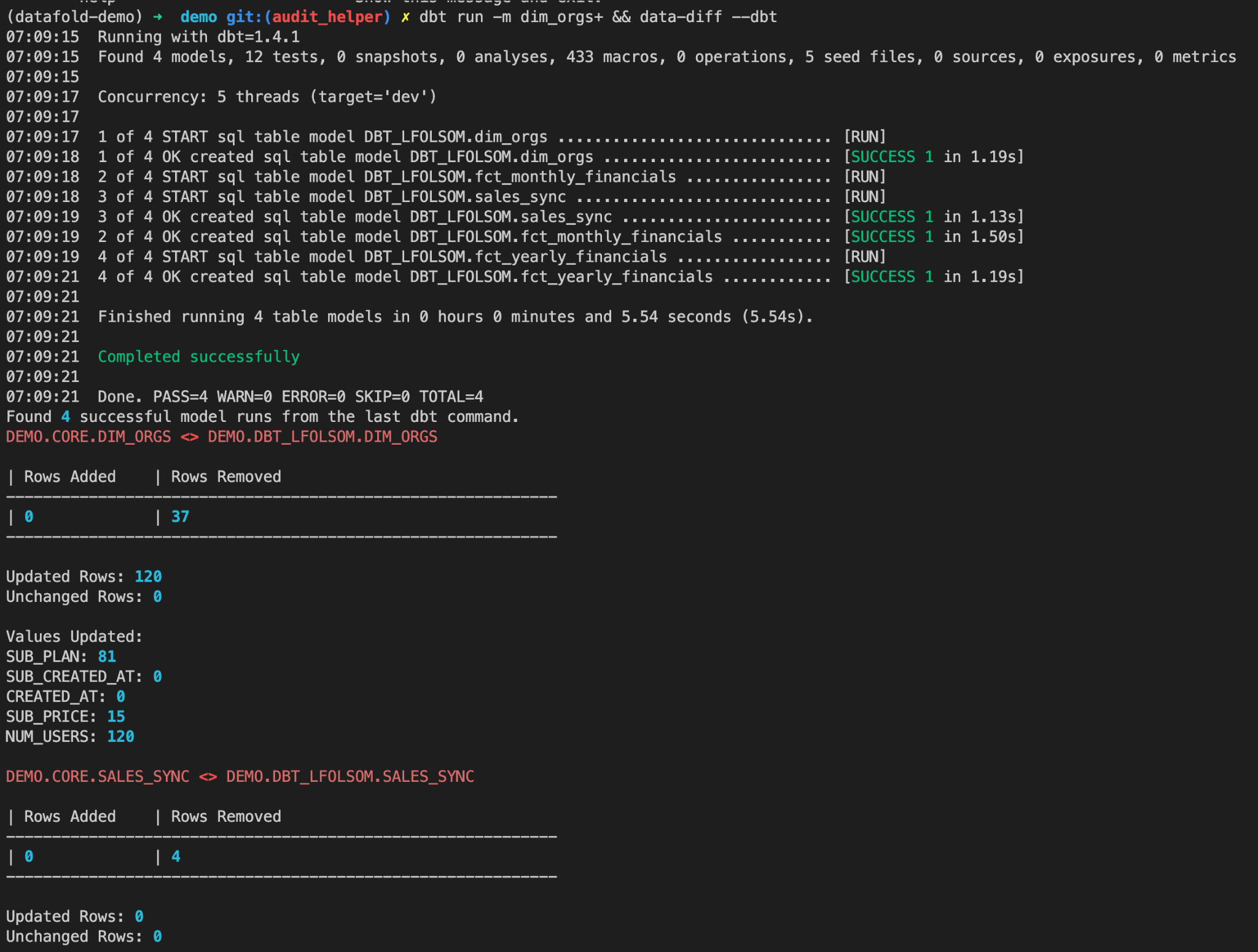
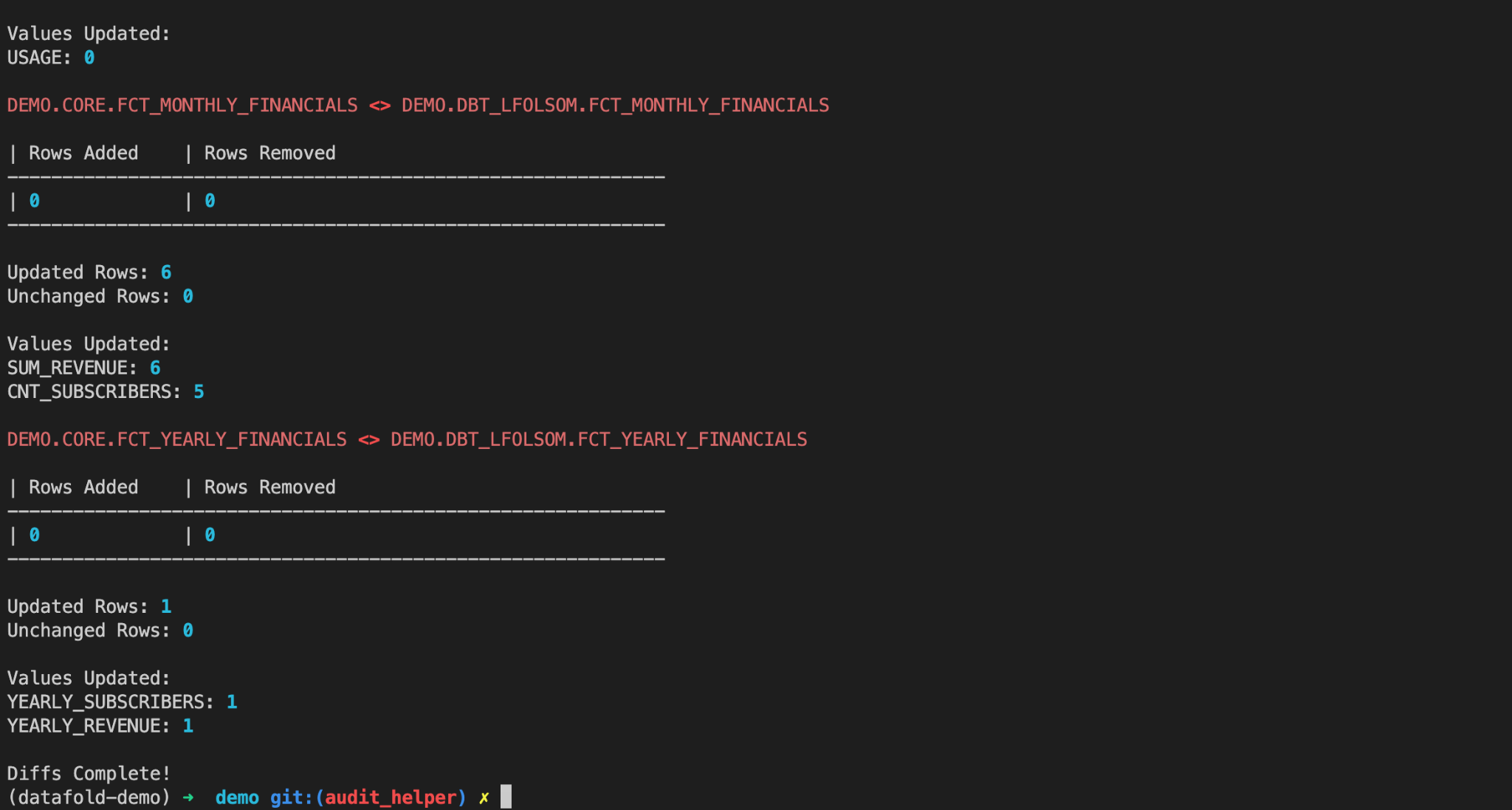
And that’s it! This gives you almost instantaneous visibility into the columns that contain non-matching values between the two data sets, as well as any primary key differences that may exist.
Importantly, it’s effortless to run data diffs on not only the table(s) you modified, but any downstream tables, or any other tables that you select in your dbt run statement.
In its present form, Datafold’s open source data-diff is limited in its ability to explore individual value differences out-of-the-box.
audit_helper for exploratory analysis vs data-diff for instantaneous diffing all relevant models
For a free, open source tool that allows deeper exploration of individual value differences, audit_helper is your best bet today.
For a quick diff of all modified and downstream models, data-diff is your best bet. The team at Datafold will soon release a free tier that lets users explore individual value-level differences in a rich visual interface.

What you’ll need to try out what I’ve walked through on your own:
- dbt-core so you can run dbt for free on your computer.
- Datafold's data-diff to see a summary of how code changes impact your data.
- dbt Labs' audit_helper to audit data differences and dive deep into analysis of specific columns. Be sure to install or upgrade to the latest version: 0.8.0.
- VS Code with dbt Power User to run dbt models and analysis and see the results right in your text editor.
- All of these tools are free and open source!
Please feel free to reach out if you have any questions or ideas as you run data diffs to be absolutely confident in the data differences between your development and production dbt environments.



